
Overview
OpenWAM is a new release for generalist world-action modeling: a benchmark-leading model, a controlled ablation suite for video-action interaction, and Generalist Joint Denoising, a new methodology for learning visual dynamics and executable control as one coupled process.
Robots do not separate knowing what might happen from choosing what to do. A drawer opening, a cloth folding, a tool slipping, a cup staying upright: these are visual futures because actions create them. Actions are useful because they resolve into physical futures.
OpenWAM starts from this seam. Instead of treating a world model and a policy as two artifacts glued together, it treats video and action as two streams in one sequence problem. The question becomes concrete: what should the model know about the future before it acts, what should an action hypothesis reveal about the future, and how should uncertainty move between the two?
The release has three layers. First, a strong generalist world-action model that reaches a new high mark in the benchmark slice reported here. Second, an ablation grammar that makes video-to-action, action-to-video, joint, decoupled, and directional noisy interaction comparable inside one stack. Third, GJD: a methodology that treats forward modeling, inverse modeling, and policy learning as different conditionings of a joint video-action denoising process.
Because the interaction rule is explicit, OpenWAM turns a philosophical boundary into an experimental variable. Should the model commit a visual future before denoising the action? Should the current action stream shape video prediction? Does bidirectional same-chunk denoising help, or does it entangle the streams too early? What remains when the same-chunk connection is severed entirely?
Initial results already show a strong signal. Under a fixed rollout protocol on LIBERO Long, the best OpenWAM primitive reaches 99.0% task-averaged success, with a large spread across interaction programs. The central claim is not only that OpenWAM is strong. It is that the structure of video-action coupling is itself a source of capability.
The seam between prediction and control is not an implementation detail. It is a modeling choice.
The release
OpenWAM combines three pieces that are usually studied separately: a world-action model, a controlled ablation framework, and a new methodology for joint video-action learning.
The model side asks whether a single generalist system can learn visual dynamics and executable control under a shared sequence contract. The ablation side asks which forms of coupling actually matter. The methodology side asks whether forward dynamics, inverse inference, and policy learning should be trained as separate modules at all.
The framework boundary is clean by design. A shared visual stack handles video latents and runtime execution; policy variants define sequence semantics and interaction programs; action decoders expose supervised robot outputs and losses. The same dataset path, checkpoint interface, rollout loop, logging surface, and evaluation code stay in place while the interaction rule changes.
The current flagship implementation uses a two-stream mixture-of-transformers policy variant. That implementation is the first concrete point in a larger space, not the boundary of the project. OpenWAM is built so new interaction paradigms can be expressed, ablated, scaled, and compared without rewriting the experimental stack around them.

Video-action interaction programs
A video-action interaction program is the unit of comparison in OpenWAM. It defines the order of generation, the visibility between streams, and the semantics of a rollout chunk.
The first release exposes a compact set of atomic programs. They are not just baselines; they are probes. Each one makes a different intervention in the information flow between seeing and acting, while the rest of the system remains fixed.
| Program | What it tests |
|---|---|
| video_then_action | Whether committing a visual future before denoising the action improves control. |
| action_then_video | Whether the current action stream should shape visual prediction before the video chunk is resolved. |
| joint | Whether video and action should denoise with bidirectional same-chunk visibility. |
| decoupled_same_step | What remains when same-chunk cross-stream attention is removed. |
| video_noisy_to_action | Whether noisy visual futures provide a useful one-way signal for action denoising. |
| action_noisy_to_video | Whether noisy action hypotheses provide a useful one-way signal for visual denoising. |
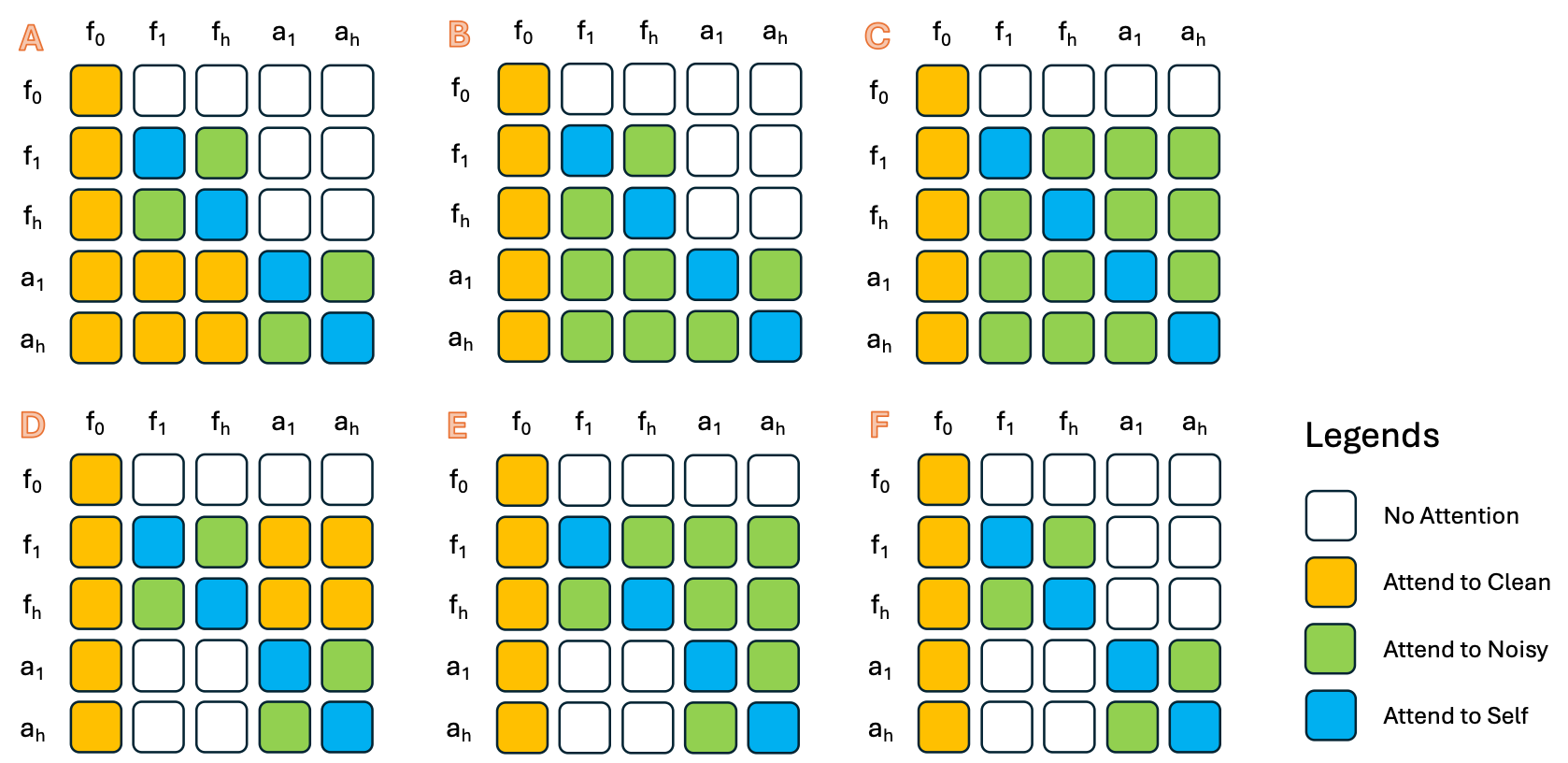
Strict semantics
Strong claims about world-action modeling need a narrow comparison surface. Every OpenWAM mode uses the same observed video prefix, target window, action alignment, loss masking, proprioceptive context policy, sampling path, and rollout protocol.
That constraint makes the result legible. A change in performance is less likely to be a story about a data loader, a checkpoint convention, a rollout cadence, or a hidden context difference. The thing allowed to move is the thing under study: the interaction program.
Design principle: when the comparison is clean, small architectural choices stop looking cosmetic. The direction and timing of video-action information flow become measurable hypotheses.
LIBERO Long results
On LIBERO Long, the interaction rule is already visible in the numbers. With fixed checkpoint selection and identical rollout settings, video_then_action reaches 99.0% task-averaged success. Other programs span from 84.0% to 97.8%, even though they run through the same stack.
The spread is the point. It turns the seam between world modeling and policy learning into an empirical object. Some couplings let the model resolve uncertainty in the right order; others force the streams to exchange information too early, too late, or not at all.
| Interaction program | Success rate | Read |
|---|---|---|
| video_then_action | 99.0% | Commit the visual future before action denoising. |
| joint | 97.8% | Denoise video and action with same-chunk bidirectional visibility. |
| action_noisy_to_video | 92.6% | Let noisy action hypotheses inform visual denoising directionally. |
| video_noisy_to_action | 92.4% | Let noisy visual futures inform action denoising directionally. |
| decoupled_same_step | 90.2% | Remove same-chunk video/action visibility. |
| action_then_video | 84.0% | Commit action before resolving the current visual chunk. |
Protocol: LIBERO Long task-averaged success rate under fixed checkpoint selection, identical rollout settings, and a shared prefix contract across interaction programs.
Generalist Joint Denoising
At the center of the next OpenWAM technical release is Generalist Joint Denoising. GJD treats video and action as a single denoising object rather than as a world model followed by a policy. Forward dynamics, inverse dynamics, and action generation become conditioning views over the same computation.
This is the methodological move that OpenWAM is built to study. The interaction programs expose the axes; GJD uses them to train a generalist world-action model in which prediction and control are resolved together.
The full mechanism belongs in the technical release. The contour is visible here: learn the agreement between what the world can do and what the robot can do, then make that agreement executable.
OpenWAM is the instrument, the model family, and the opening move for GJD.
Release path
The public OpenWAM release is organized around reproducible world-action modeling. It includes configurable training recipes, evaluation and rollout scripts, static config validation, checkpoint loading utilities, and validated paths for video-action policy training.
The first layer opens the grammar: interaction programs, strict semantics, and controlled benchmark comparisons. The next layer opens the methodology: GJD, streaming visual rollout, cache semantics, checkpoint selection, and broader benchmark reproducibility.
OpenWAM is not another policy variant added to a leaderboard. It is an attempt to make the boundary between seeing and acting a first-class object, then show that moving that boundary improves generalist robot learning.